การประมวลผลภาพด้วยเครื่องคอมพิวเตอร์ Image processing
ขั้นตอนที่ 3 การจำแนกประเภทข้อมูลภาพ (Image classification) การจำแนกประเภทข้อมูลภาพเป็นการประมวลผลในทางสถิติ เพื่อแยกข้อมูลจุดภาพทั้งหมดที่ประกอบเป็นพื้นที่ศึกษาออกเป็นกลุ่มย่อย โดยใช้ลักษณะทางสถิติเป็นตัวกำหนดความแตกต่างระหว่างกลุ่มจุดภาพ โดยจุดภาพที่ถูกจัดให้อยู่กลุ่มเดียวกันจะมีลักษณะทางสถิติเฉพาะกลุ่มเป็นไปในทิศทางเดียวกัน แต่ละกลุ่มจุดภาพที่จำแนกได้นั้นจะแสดงถึงสิ่งปกคลุมพื้นดินประเภทใดประเภทหนึ่งแตกต่างกันไป
กล่าวอีกนัยหนึ่ง การจำแนกประเภทข้อมูลภาพ หมายถึง การแบ่งจุดภาพที่มีคุณสมบัติการสะท้อนแสงคล้ายๆ กันออกเป็นกลุ่มหรือเป็นระดับ ซึ่งเรียกว่า ชนิดหรือประเภท (Class) เพื่อที่จะแบ่งแยกวัตถุต่างๆ ที่แสดงในภาพออกจากกัน ในการจำแนกประเภทข้อมูลนี้ผู้ปฏิบัติต้องใช้กฎการตัดสินใจหรือความรู้ทางสถิติเข้าช่วย เนื่องจากปริมาณจุดภาพที่ประกอบเป็นพื้นที่ศึกษา มีปริมาณจุดภาพมากการคำนวณทางสถิติเองโดยใช้เครื่องคิดเลขจึงทำได้ยากใช้เวลามากและอาจเกิดข้อผิดพลาดได้ จึงมีการนำเอาความสามารถของคอมพิวเตอร์มาช่วยในการประมวลผล ทำให้ได้ผลลัพธ์ในเวลารวดเร็วสามารถตรวจสอบความถูกต้องได้ทันที
การจำแนกประเภทข้อมูลภาพด้วยระบบคอมพิวเตอร์แบ่งออกได้เป็น 2 วิธี คือ การจำแนกประเภทข้อมูลภาพแบบควบคุม (Supervised classification) และการจำแนกประเภทข้อมูลภาพแบบไม่ควบคุม(Unsupervised classification) การจำแนกประเภทข้อมูลภาพทั้งสองวิธีให้ได้ผลลัพธ์ที่มีประสิทธิภาพนั้น ก่อนเริ่มจำแนกประเภทข้อมูลภาพ ควรศึกษาสถิติของข้อมูลภาพในแต่ละช่วงคลื่นเสียก่อน ทั้งนี้เพื่อให้ได้ช่วงคลื่นที่เหมาะสมในการใช้จำแนกประเภทข้อมูลภาพ ค่าสถิติเบื้องต้นที่ใช้ในการเลือกช่วงคลื่นที่เหมาะสม ได้แก่
– ค่าการสะท้อนต่ำสุด-สูงสุด (Minimum-Maximum value) ของแต่ละช่วงคลื่น เป็นค่าที่แสดงการสะท้อนของข้อมูลภาพในแต่ละช่วงคลื่นว่ามีค่าการสะท้อนตกอยู่ในช่วงใด ระหว่างค่า 0-255 หากเป็นค่าที่อยู่ใกล้ 0 มาก หมายถึง ช่วงคลื่นนั้นจะให้ข้อมูลเกี่ยวกับวัตถุที่มีการดูดกลืนพลังงานมาก หากค่าค่อนไปทาง 255 หมายถึงช่วงคลื่นนั้นจะให้ข้อมูลเกี่ยวกับวัตถุที่มีการสะท้อนพลังงานสูง และหากมีช่วงค่ากว้าง คือ มีทั้งค่าต่ำสุดใกล้ 0 และมีค่าสูงสุดใกล้ 255 หมายถึง มีข้อมูลของกลุ่มวัตถุทั้งที่ดูดกลืนพลังงานและที่สะท้อนพลังงาน ถือเป็นช่วงคลื่นที่มีความหลากหลายของข้อมูลมาก
– ค่าเฉลี่ยเลขคณิต (Mean) เป็นค่าเฉลี่ยค่าการสะท้อนทั้งหมดของแต่ละช่วงคลื่น สามารถใช้เป็นตัวแทนภาพรวมข้อมูลจุดภาพทั้งหมดของช่วงคลื่นหนึ่งๆ ได้ ค่าเฉลี่ยเลขคณิตสามารถคำนวณโดยนำผลบวกของค่าการสะท้อนทั้งหมดมาหารด้วยจำนวนจุดภาพทั้งหมด ดังนี้
โดย x̄ = ค่าเฉลี่ยเลขคณิต
X = ค่าการสะท้อนของแต่ละจุดภาพ
N = จำนวนจุดภาพทั้งหมด
– ค่าเฉลี่ยเลขคณิตนิยมใช้ในการวัดค่าเฉลี่ยค่าการสะท้อนของจุดภาพมากที่สุด โดยจะเป็นค่าเฉลี่ยที่ดีนั้นต่อเมื่อข้อมูลจุดภาพทั้งหมดมีการแจกแจงค่าการสะท้อนในลักษณะสมมาตรหรือการแจกแจงของคะแนนไม่มีความเบ้ (Skewness) ซึ่งสามารถตรวจสอบลักษณะการแจกแจงของคะแนนได้จากการนำเอาค่าการสะท้อนของทุกจุดภาพมาสร้างเป็นแผนภูมิภาพของข้อมูลภาพ ดังรูป

– ค่ากึ่งกลาง (Median) เป็นการวัดแนวโน้มเข้าสู่ส่วนกลางวิธีหนึ่งที่ใช้การเรียงค่าการสะท้อนของจุดภาพจากค่าน้อยที่สุดไปหาค่ามากที่สุด โดยค่ากึ่งกลางเป็นค่าที่อยู่ในตำแหน่งกึ่งกลางของข้อมูลทั้งชุด ค่ากึ่งกลางจึงเป็นตัวแทนค่าการสะท้อนของจำนวนจุดภาพทั้งหมดในช่วงคลื่นหนึ่งๆ ที่แสดงให้ทราบว่ามีจำนวนจุดภาพที่มีค่าการสะท้อนมากกว่าและน้อยกว่าค่ากึ่งกลางอยู่ประมาณร้อยละ 50
– ค่าฐานนิยม (Mode) เป็นการวัดแนวโน้มเข้าสู่ส่วนกลางอีกวิธีหนึ่ง โดยดูจากจำนวนความถี่ของค่าการสะท้อนซึ่งมีความถี่สูงที่สุด นิยมนำมาใช้กับข้อมูลที่เป็นนามบัญญัติ เช่น ค่าของประเภทข้อมูลหลังจากการจำแนกประเภทแล้ว ถือเป็นค่าการสะท้อนที่แสดงการใช้ที่ดินประเภทต่างๆ ไม่ใช่ค่าการสะท้อนของวัตถุอีกต่อไป
– ความเบี่ยงเบนมาตรฐาน (Standard Deviation : S.D.) เป็นการวัดการกระจายที่นิยมใช้มากที่สุดการคำนวณใช้วิธียกกำลังสองของผลต่างระหว่างค่าการสะท้อนของทุกจุดภาพในแต่ละช่วงคลื่นกับค่าเฉลี่ยเลขคณิตของช่วงคลื่นนั้น มีสูตรในการคำนวณ ดังนี้

โดย S.D. = ความเบี่ยงเบนมาตรฐาน
X = ค่าการสะท้อนของแต่ละจุดภาพ
x̄ = เฉลี่ยเลขคณิต
N = จำนวนจุดภาพทั้งหมด
ค่าความแปรปรวน (Variance – σ) เป็นการวัดการกระจายเช่นเดียวกับความเบี่ยงเบนมาตรฐานคำนวณได้จากค่าเฉลี่ยของผลรวมทั้งหมดของคะแนนเบี่ยงเบนยกกำลังสอง
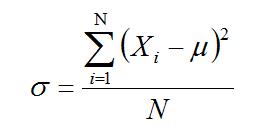
โดย Xi = ค่าการสะท้อนของจุดภาพ มีค่าตั้งแต่ 1- N
μ = ค่าเฉลี่ยเลขคณิตของประชากรจุดภาพทั้งหมด
N = จำนวนจุดภาพทั้งหมด
– สหสัมพันธ์ (Correlation) เป็นการวัดความสัมพันธ์ระหว่างข้อมูลตั้งแต่ 2 ชุดขึ้นไป วัดได้จากการคำนวณหาสัมประสิทธิ์สหสัมพันธ์ (Correlation coefficient) มีขอบเขตตั้งแต่ 0 ถึง + 1.00 เมื่อค่าสัมประสิทธิ์สหสัมพันธ์ระหว่างข้อมูลภาพ 2 ช่วงคลื่น เข้าใกล้ 1.00 หมายถึง ข้อมูลทั้ง 2 ชุดนั้น มีความสัมพันธ์ต่อกันในระดับสูงซึ่งอาจจะมีความสัมพันธ์โดยตรง (ค่าสัมประสิทธิ์สหสัมพันธ์เป็นค่าลบ) และเมื่อสัมประสิทธิ์สหสัมพันธ์เข้าใกล้ 0 หมายถึง ข้อมูลทั้ง 2 ช่วงคลื่นมีความสัมพันธ์กันในระดับต่ำหรือแตกต่างกันเป็นประโยชน์ในการเลือกช่วงคลื่นในการจำแนกประเภท
ในการศึกษาความสัมพันธ์ระหว่างช่วงคลื่น 2 ประเภท ทำได้โดยให้แสดงการกระจายของค่าการสะท้อนของจุดภาพลงบนกราฟแบบ 2 แกน โดยแกนที่ 1 เป็นค่าการสะท้อนของช่วงคลื่นที่ 1 และแกนที่ 2 เป็นค่าการสะท้อนของช่วงคลื่นที่ 2 หรือเรียกว่า การทำตารางไขว้ (Cross tabulation) รูปแบบการกระจายของค่าการสะท้อนจะบอกถึงลักษณะความสัมพันธ์ของข้อมูลในสองช่วงคลื่นได้เช่นเดียวกับค่าสัมประสิทธิ์สหสัมพันธ์
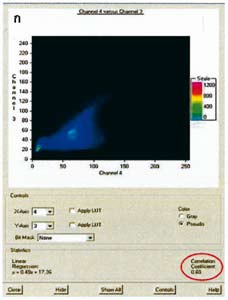
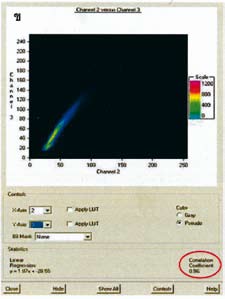
วิธีทางสถิติที่กล่าวข้างต้น มีประโยชน์อย่างยิ่งในการนำมาใช้เลือกช่วงคลื่นให้เหมาะสมกับงานที่ทำศึกษา เมื่อเลือกช่วงคลื่นที่เหมาะสมแล้ว สามารถนำช่วงคลื่นเหล่านั้นมาจำแนกประเภทข้อมูลภาพเพื่อให้ได้ผลลัพธ์ที่มีประสิทธิภาพต่อไป
1) การจำแนกประเภทข้อมูลแบบควบคุม
การจำแนกประเภทข้อมูลแบบควบคุม เป็นการจำแนกประเภทข้อมูลที่ผู้ใช้งานเป็นผู้กำหนดลักษณะของประเภทข้อมูลเอง โดยเป็นผู้เลือกตัวอย่างประเภทข้อมูลให้แก่เครื่อง จึงเรียกการจำแนกข้อมูลประเภทนี้ว่าเป็นวิธีแบบควบคุมโดยผู้วิเคราะห์ต้องควบคุมอย่างใกล้ชิด ข้อมูลตัวแทนหรือข้อมูลตัวอย่างที่ผู้ใช้งานเป็นผู้กำหนดนั้นได้จากการตีความหมายภาพดาวเทียมที่ถูกต้องด้วยสายตาโดยอาศัยประสบการณ์ ความเข้าใจและความรู้ที่มีอยู่ ตลอดจนกระบวนการต่างๆ ในการตีความหมาย เช่น การสำรวจภาคสนาม การใช้แผนที่ภาพถ่ายต่างๆ และสถิติอื่นๆ เป็นต้นทั้งนี้เพื่อให้ได้มาซึ่งข้อมูลที่มีความหมายถูกต้องตามระบบการจำแนก ตัวอย่างที่เลือกเป็นข้อมูลทางสถิติที่กำหนดคุณลักษณะของข้อมูล ซึ่งเครื่องคอมพิวเตอร์จะนำคุณลักษณะทางสถิติของพื้นที่ตัวอย่างนั้นไปทำการประมวลผลแล้วจำแนกแต่ละจุดภาพของข้อมูลดาวเทียมให้เป็นประเภทข้อมูลตามที่ผู้ใช้งานกำหนดไว้ตามพื้นที่ตัวอย่าง ซึ่งความถูกต้องและความน่าเชื่อถือของการจำแนกวิธีนี้ขึ้นอยู่กับคุณลักษณะของพื้นที่ตัวอย่างว่ามีความหลากหลายครอบคลุมทุกประเภทข้อมูลหรือไม่และเป็นตัวแทนของประชากรข้อมูลทุกประเภทหรือไม่ วิธีการนี้ผู้ใช้งานจะต้องมีความรู้ในพื้นที่ศึกษาเป็นอย่างดี โดยศึกษาจากข้อมูลเสริมประกอบตลอดจนการสังเกตลักษณะเชิงกายภาพ (Physical characteristics) ของประเภทข้อมูลดังที่กล่าวมาแล้วข้างต้น
1.1) การเลือกตัวอย่างประเภทข้อมูล (Sampling of training sites/ areas) เป็นสิ่งจำเป็นสำหรับการจำแนกข้อมูลแบบควบคุม การเลือกพื้นที่ตัวอย่างต้องอาศัยความช่างสังเกตการใช้ที่ดินลักษณะต่างๆ เป็นอย่างดีและพยายามแยกประเภทตัวอย่างให้ละเอียดครบทุกลักษณะทางกายภาพของการใช้ที่ดินและสิ่งปกคลุมดิน โดยมีหลักการในการเลือกพื้นที่ตัวอย่าง ดังนี้
– ควรเลือกตัวอย่างที่เป็นตัวแทนของประเภทการใช้ที่ดิน และสิ่งปกคลุมดินทุกประเภทในพื้นที่ศึกษา
– ควรเลือกแปลงพื้นที่ตัวอย่างของการใช้ที่ดินชนิดเดียวกันให้กระจายทั่วพื้นที่ศึกษา เพื่อเป็นตัวแทนของลักษณะประเภทการใช้ที่ดินนั้นๆ
– ควรเลือกจำนวนจุดภาพต่อตัวอย่างการใช้ที่ดินแต่ละประเภทให้มีจำนวนมากกว่า 30 จุดภาพขึ้นไป เพื่อให้มีตัวแทนทางสถิติที่มีลักษณะเป็นการกระจายแบบปกติ
– ควรเลือกตัวอย่างที่มีสีกลุ่มเดียวกันหรือมีลักษณะเป็นเนื้อเดียวกัน (Homogeneous) ทั้งนี้เพื่อลดการปะปนกับตัวอย่างประเภทอื่น พื้นที่ตัวอย่างที่มีความเป็นเนื้อเดียวกันมากถือเป็นตัวอย่างข้อมูลที่ดี
การเลือกพื้นที่ตัวอย่างทำได้โดยการวงขอบเขตพื้นที่ตัวอย่างที่ต้องการเลือกจากหน้าจอคอมพิวเตอร์เมื่อได้ขอบเขตของพื้นที่ตัวอย่างของทุกประเภทการใช้ที่ดินแล้วขั้นตอนต่อไป คือ การเลือกตัวอย่างจากช่วงคลื่นที่จะใช้ประมวลผล ตัวอย่างจากแต่ละช่วงคลื่นจะมีค่าสถิติซึ่งสามารถนำมาวิเคราะห์ทางสถิติ เพื่อประเมินว่าตัวอย่างที่เลือกได้ตามช่วงคลื่นต่างๆ มีความน่าเชื่อถือ และเป็นตัวแทนที่ดีหรือไม่ สถิติที่สำคัญ คือ ค่าการสะท้อนต่ำสุด-สูงสุดของประเภทการใช้ที่ดินนั้น ค่าสะท้อนเฉลี่ย ค่าความแปรปรวน ตารางความแปรปรวนร่วม และตารางสหสัมพันธ์
1.2) การศึกษาลักษณะทางสถิติของพื้นที่ตัวอย่าง
สำหรับข้อมูลจากดาวเทียมแต่ละจุดภาพมีค่าเป็น 3 มิติ คือ ค่าพิกัดตั้ง (i) ค่าพิกัดแนวนอน (j) และความสว่างของจุดภาพ (BV) แต่ละจุดภาพมีลักษณะความสว่างแตกต่างตามแต่ละช่วงคลื่นเป็นลักษณะเวกเตอร์ของจุดภาพ ดังนี้

หากเลือกพื้นที่ตัวอย่างแล้ว แต่ละตัวอย่างจะมีค่าเฉลี่ยของแต่ละประเภทข้อมูล (Class) ในรูปเวกเตอร์ดังนี้

ตัวอย่างสมมติให้มีการเลือกพื้นที่ตัวอย่างการใช้ที่ดิน 3 ประเภท (3 classes) ได้แก่ แหล่งน้ำ (Water) ป่าไม้ (Forest) และย่านการค้า (Build up area) ของข้อมูลจากดาวเทียม LANDSAT ระบบ TM จำนวน 6 ช่วงคลื่น (bands 1 5 และ 7) เมื่อเลือกพื้นที่ตัวอย่างแล้วได้ข้อมูลสถิติของพื้นที่ตัวอย่าง
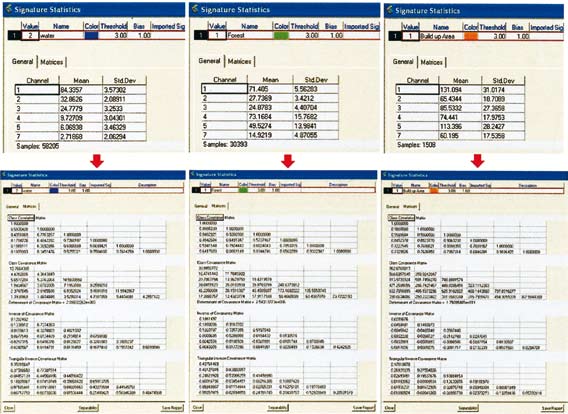
ค่าสถิติของพื้นที่ตัวอย่างที่นิยมนำมาวิเคราะห์ ได้แก่
1.2.1) ค่าสะท้อนเฉลี่ยจากจุดภาพของแต่ละพื้นที่ตัวอย่าง นำมาวิเคราะห์ลักษณะบ่งชี้หรือลายเซ็นเชิงคลื่น (Spectral signature) เพื่อดูความแตกต่าง หรือความคล้ายคลึงระหว่างประเภทข้อมูลต่างๆ
จากภาพลายเซ็นเชิงคลื่นของการใช้ที่ดินทั้ง 3 ประเภท มีลักษณะตรงตามค่าการสะท้อนเชิงทฤษฎี และไม่มีลักษณะเหมือนกัน กล่าวคือ ย่านการค้ามีค่าการสะท้อนสูงที่สุด เส้นลายเซ็นเชิงคลื่นไม่ซ้อนทับกับเส้นการใช้ที่ดินประเภทอื่น เป็นลักษณะลายเซ็นเชิงคลื่นของดิน-แร่ธาตุ โดยเฉพาะการสะท้อนสูงในช่วงคลื่นที่ 3 (คลื่นตามองเห็น) และ 5 (คลื่นอินฟราเรดคลื่นสั้น) เพราะเป็นอาคารสิ่งปลูกสร้างที่เป็นวัตถุสะท้อนพลังงานสูง (ซีเมนต์ คอนกรีต) ป่าไม้แสดงการสะท้อนของพืช มีค่ามากที่สุดในช่วงคลื่นที่ 4 (คลื่นอินฟราเรดใกล้) ซึ่งพืชมีค่าการสะท้อนสูงที่สุดส่วนแหล่งน้ำมีลักษณะการสะท้อนอยู่ในกลุ่มของน้ำ คือ มีค่าลดลง (เนื่องจากการดูดกลืนพลังงาน) ในกลุ่มช่วงคลื่นอินฟราเรด ยกเว้นพื้นที่ชุ่มน้ำ ที่ช่วงคลื่นที่ 5 มีค่าสูงขึ้นเล็กน้อย เพราะน้ำมีสิ่งเจือปน
1.2.2) ค่าความแปรปรวน เป็นการวัดความแตกต่างของข้อมูล โดยทั่วไปค่าความแปรปรวนของวัตถุกลุ่มน้ำจะมีค่าต่ำที่สุด มีลักษณะเป็นเอกพันธ์มาก ค่าความแปรปรวนของพืชมีมากขึ้น และกลุ่มย่านการค้ามีค่าความแปรปรวนมากที่สุด เพราะมีการปะปนของวัตถุต่างประเภทกันมากที่สุด
1.2.3) ค่าสหสัมพันธ์ มีประโยชน์ในการเลือกช่วงคลื่นที่จะใช้ในการคำนวณโดยช่วงคลื่นที่มีความสัมพันธ์สูงจะให้ข้อมูลเช่นเดียวกัน เช่น ช่วงคลื่นในกลุ่มคลื่นตามองเห็น ช่วงคลื่นอินฟราเรดกลางจึงไม่จำเป็นที่จะต้องใช้ทั้งหมด สามารถเลือกใช้ช่วงคลื่นที่มีความสัมพันธ์ต่ำ และลดจำนวนข้อมูลในการคำนวณ ทำให้การคำนวณเร็วมากขึ้น
เมื่อผู้ใช้ทำการกำหนดพื้นที่ตัวอย่างและทำการวิเคราะห์ค่าสถิติของพื้นที่ตัวอย่างแล้ว ขั้นต่อไปผู้ใช้ต้องทำการกำหนดวิธีการจำแนกประเภทข้อมูลภาพให้กับคอมพิวเตอร์ โดยวิธีการที่นิยมใช้ในการจำแนกประเภทข้อมูลภาพ ได้แก่
1.3) กฎการตัดสินใจเพื่อการจำแนกข้อมูลภาพ (Classification decision rules)
1.3.1) กฎการตัดสินใจเพื่อการจำแนกข้อมูลภาพแบบระยะห่างต่ำสุด (Minimum distance to means) เป็นกฎการจำแนกที่ง่ายที่สุดและทำงานได้เร็วที่สุดประกอบด้วย 3 ขั้นตอน คือ
– การคำนวณค่าเฉลี่ยจำนวนตัวเลข (DN) ของข้อมูลตัวอย่างจากทุกช่วงคลื่น ค่าเฉลี่ยนี้เรียกว่า เวกเตอร์ ค่าเฉลี่ย (Mean vector)
– จำนวนจุดภาพทั้งหมดที่อยู่ในข้อมูลที่จะนำมาจำแนกนั้น ถูกจัดให้อยู่ในชั้นข้อมูลที่อยู่ใกล้เวกเตอร์ ค่าเฉลี่ยของชั้นนั้น
– แนวขอบเขตของข้อมูล (Data boundary) ถูกกำหนดให้อยู่รอบเวกเตอร์ค่าเฉลี่ย ดังนั้นหากจุดภาพใดตกอยู่นอกขอบเขตก็จะถูกจำแนกเป็นค่าที่ไม่ทราบ (Unknown)

ที่มา : Aronoff, S. (2005)
จากภาพ จุดภาพที่ไม่ทราบว่าเป็นข้อมูลชนิดใด(Unknown pixel) แสดงโดยจุดที่ 1 ระยะทางระหว่างจุดภาพนี้กับค่าเฉลี่ยของชั้นข้อมูล แสดงได้โดยเส้นประ ภายหลังที่การคำนวณเสร็จสิ้นลงแล้วจุดภาพที่ไม่ทราบก็จะถูกจัดเป็นชั้นข้อมูลที่มีระยะทางใกล้กับค่าเฉลี่ยของของชั้นข้อมูลนั้น ในกรณีนี้คือ C ถ้าหากว่าจุดภาพที่ไม่ทราบค่านี้มีระยะทางห่างจากค่าเฉลี่ยของแต่ละชั้นข้อมูลมากเกินกว่าระยะทางที่ผู้ทำการวิเคราะห์ได้กำหนดไว้ จุดภาพนั้นก็จะไม่สามารถถูกจัดให้เป็นชั้นข้อมูลชนิดใดชนิดหนึ่งได้ จึงถูกจัดเป็นจุดภาพที่ไม่สามารถจำแนกประเภทได้ (Unclassified pixel)
การจำแนกประเภทข้อมูลแบบระยะห่างต่ำสุด ให้ผลลัพธ์ที่ดีกว่าการจำแนกประเภทข้อมูลแบบสี่เหลี่ยมคู่ขนาน และจะไม่มีจุดภาพใดที่ไม่ถูกการจำแนก แต่จะมีการคำนวณมากขึ้น และมีข้อเสียหากระยะห่างต่ำสุดของจุดภาพ ใกล้เคียงกับกลุ่มประเภทข้อมูลมากกว่า 1 กลุ่ม การจำแนกให้จุดภาพนั้นเข้าไปอยู่ในประเภทข้อมูลหนึ่งอาจมีความผิดพลาดได้
อย่างไรก็ตามในการจำแนกประเภทข้อมูลโดยวิธีนี้มีข้อจำกัดหลายอย่างแต่ที่สำคัญที่สุดคือ ทำงานได้ไม่ค่อยมีประสิทธิภาพกับข้อมูลที่มีความแปรปรวนแตกต่างกันมาก เช่น จุดภาพที่ 2 อยู่ใกล้ U แต่ถูกจัดให้อยู่ในกลุ่ม S แทนที่จะจัดให้อยู่ในกลุ่ม U เนื่องจากมีค่าความผันแปรในชั้นข้อมูลสูงกว่า ทำให้มีระยะทางห่างจากจุดศูนย์กลางมากกว่า ดังนั้นจึงไม่ค่อยนิยมใช้กันมากนักกับชั้นข้อมูลที่มีค่าการสะท้อนแสงใกล้เคียงกันและมีความแปรปรวนสูง (Lillessand and Kiefer, 1994)
1.3.2) กฎการตัดสินใจเพื่อการจำแนกข้อมูลภาพแบบสี่เหลี่ยมคู่ขนาน (Parallelepiped classification or Box classifier)
เป็นการจำแนกที่นิยมใช้มากที่สุดในงานประมวลผลข้อมูลเพราะทำงานได้รวดเร็วมีขีดความสามารถในการคำนวณสูง การทำงานของวิธีนี้เป็นการจำแนกจุดภาพออกโดยกำหนดค่าจำนวนตัวเลขต่ำสุดและสูงสุดของแต่ละช่วงคลื่น หรือใช้ค่าเบี่ยงเบนมาตรฐานเสมือนกับเอากรอบสี่เหลี่ยมไปวางรอบๆ ชั้นข้อมูลในข้อมูลตัวอย่าง จุดภาพก็จะถูกจำแนกตามกลุ่มที่ตกอยู่ในขอบเขตของกรอบสี่เหลี่ยมหนึ่ง ดังภาพที่ 3.54 จุดภาพที่ 2 ก็จะถูกจัดให้อยู่ในชั้น U เป็นต้น การจำแนกประเภทข้อมูลแบบสี่เหลี่ยมคู่ขนาน มีข้อดีที่สามารถคำนวณได้ผลลัพธ์รวดเร็ว เนื่องจากวิธีการคำนวณไม่ซับซ้อน แต่มีข้อบกพร่องที่จะเกิดการปะปนของประเภทข้อมูลสูง เพราะค่าต่ำสุด ค่าสูงสุดบางส่วนของแต่ละประเภทข้อมูล จะเกิดการตกอยู่ในช่วงค่าเดียวกัน จนเครื่องไม่สามารถจัดเข้ากลุ่มใดได้ เกิดเป็นข้อมูลที่จำแนกประเภทไม่ได้ จำนวนมาก หรือกล่าวได้ว่าถ้าขอบสี่เหลี่ยมซ้อนกัน ก็จะทำให้เกิดความยากในการตัดสินในการจัดจุดภาพให้อยู่ในชั้นข้อมูลประเภทใด การเหลื่อมกันของรูปสี่เหลี่ยมนี้มีโอกาสเกิดขึ้นสูงกับข้อมูลที่มีค่าสหสัมพันธ์สูง (Highcorrelation) หรือค่าความแปรปรวนร่วมสูง (High covariance) อย่างไรก็ตามปัญหานี้สามารถทำการแก้ไขได้โดยการปรับขนาดของกรอบสี่เหลี่ยมให้มีขนาดเล็กลงมีลักษณะคล้ายกับขั้นบันไดดังภาพ


1.3.3) กฎการตัดสินใจเพื่อการจำแนกข้อมูลภาพแบบความน่าจะเป็นไปได้สูงสุด(Maximum likelihood classifier)

ที่มา : Aronoff, S. (2005)
เป็นวิธีที่มีความถูกต้องมากที่สุดแต่ใช้เวลาในการคำนวณมากเมื่อเปรียบเทียบกับวิธีอื่นๆ (Curran, 1985) หลักการทำงานคือ ครั้งแรกจะต้องมีการคำนวณเวกเตอร์เฉลี่ย ค่าแปรปรวน และค่าสหสัมพันธ์ของช่วงคลื่นที่นำมาใช้ในการจำแนกประเภทของชั้นข้อมูลจากข้อมูลตัวอย่างโดยตั้งอยู่บนสมมติฐานที่ว่าแต่ละชั้นข้อมูลจะต้องมีการกระจายตัวเป็นแบบปกติ (Normal distribute) การกระจายตัวของจุดภาพรอบๆ ค่าเฉลี่ย อธิบายได้โดยทฤษฎีของความน่าจะเป็นหรือ“Probability Function” เช่น ในภาพที่ 3.56 จุดภาพที่ 1 จะถูกจัดให้อยู่ในชั้น C เป็นต้น
ข้อเสียเปรียบของการจำแนกประเภทข้อมูลชนิดนี้คือใช้เวลาในการคำนวณมากเพื่อที่จะจำแนกค่าของจุดภาพแต่ละค่าให้อยู่ในประเภทใดประเภทหนึ่ง โดยเฉพาะอย่างยิ่งถ้าทำงานกับข้อมูลช่วงคลื่น หรือใช้ข้อมูลที่มีกลุ่มค่าการสะท้อนแสงที่แตกต่างกันจำนวนมาก ดังนั้นการทำงานจึงช้ากว่าวิธีการที่กล่าวมาแล้วข้างต้นปัญหาดังกล่าวสามารถที่จะแก้ไขได้โดยการนำวิธีการต่างๆ มาใช้ เช่น การลดขนาดของข้อมูลก่อนที่จะนำมาใช้ในการจำแนกประเภทเป็นต้น
2) การจำแนกประเภทข้อมูลแบบไม่ควบคุม (Unsupervised classification)
เป็นวิธีการจำแนกประเภทข้อมูลที่ผู้วิเคราะห์ไม่ต้องกำหนดพื้นที่ตัวอย่างของข้อมูลแต่ละประเภทให้กับคอมพิวเตอร์ มักจะใช้ในกรณีไม่มีข้อมูลเพียงพอในพื้นที่ที่ทำการจำแนก หรือผู้ใช้ไม่มีความรู้ความเคยชินในพื้นที่ศึกษาวิธีการนี้สามารถทำได้โดยสุ่มตัวอย่างแบบคละ แล้วจึงนำกลุ่มข้อมูลดังกล่าว มาแบ่งเป็นประเภทต่างๆ โดยแต่ละประเภทมีลักษณะเชิงคลื่นที่เหมือนกัน โดยใช้เทคนิคการรวมกลุ่ม (Clustering) ซึ่งแบ่งออกเป็นสองแบบ คือ
2.1) การรวมกลุ่มแบบลำดับชั้น (Hierarchical clustering) วิธีนี้จุดภาพจะถูกจัดรวมเป็นกลุ่มที่คล้ายกันโดยใช้ระยะห่างเป็นเครื่องวัด เริ่มต้นด้วยการสมมติว่าแต่ละจุดภาพเป็น 1 กลุ่ม จุดภาพที่มีระยะห่างกันน้อยที่สุดก็จะรวมตัวเข้าด้วยกัน ถัดจากนั้นจะเป็นการรวมกลุ่มจุดภาพไปเรื่อยๆ จนกระทั่งได้กลุ่มตามจำนวนที่กำหนดไว้จึงหยุด
2.2) การรวมกลุ่มแบบไม่เป็นลำดับชั้น (Non-hierarchical clustering) เริ่มต้นด้วยการแบ่งข้อมูลออกเป็นกลุ่มชั่วคราวจำนวนหนึ่ง หลังจากนั้นสมาชิกในแต่ละกลุ่มจะถูกตรวจสอบโดยใช้ตัวแปรหรือระยะห่างที่เลือกมาเพื่อทำการจัดตำแหน่งใหม่ให้อยู่ในกลุ่มที่เหมาะสมกว่าโดยมีการแบ่งกลุ่มชัดเจนดีขึ้น ตัวอย่างของการรวมกลุ่มวิธีนี้ได้แก่ วิธี ISODATA และวิธี K-mean
นิยามของระยะห่างที่ใช้ในการวัดความคล้ายกันมีหลายแบบ (สำนักงานคณะกรรมการวิจัยแห่งชาติ, 2540) เช่น
– วิธีตำแหน่งใกล้ที่สุด (Nearest neighbor method) ตำแหน่งใกล้สุดมีระยะห่างต่ำสุดจะรวมเป็นกลุ่มใหม่
– วิธีตำแหน่งไกลที่สุด (Furthest neighbor method) ตำแหน่งใกล้สุดมีระยะห่างมากสุดจะรวมเป็นกลุ่มใหม่
– วิธีจุดรวมมวล (Centroid method) ระยะห่างจากจุดศูนย์ถ่วงของสองกลุ่มจะถูกวัด เพื่อดูว่าจะสามารถรวมตัวกันเป็นกลุ่มใหม่ได้หรือไม่
– วิธีเฉลี่ยระหว่างกลุ่ม (Group average method) รากของกำลังสองเฉลี่ยของระยะห่างระหว่างทุกๆคู่ของข้อมูลในกลุ่มที่ต่างกันสองกลุ่ม จะนำมาใช้เป็นเกณฑ์ในการสร้างกลุ่ม
– วิธีวอร์ด (Ward method) รวมกลุ่มเก่าเข้าเป็นกลุ่ม โดยพยายามให้รากกำลังสองเฉลี่ยของระยะห่างระหว่างศูนย์ถ่วงกับทุกๆ ข้อมูลที่เป็นสมาชิกเพิ่มขึ้นน้อยที่สุด
ที่มา : ตำราเทคโนโลยีอวกาศและภูมิสารสนเทศศาสตร์